

Η APU Strix Point “Ryzen AI 9 365” Zen 5 της AMD φέρεται να έχει δοκιμαστεί από
Ντέιβιντ Χουάνγκ
ο οποίος έχει μια εις βάθος ανάλυση του IPC, του λανθάνοντος χρόνου και της
απόδοση
ς.
Η
AMD Ryzen
AI 9 365 “Strix Point” APU δοκιμάζεται σε πληθώρα σημείων αναφοράς πριν από την κυκλοφορία, IPC, απόδοση, καθυστέρηση και περισσότερες λεπτομέρειες του Zen 5
Σημείωση –
Το ιστολόγιο του David Huang αναφέρει ότι οι αριθμοί που αναφέρονται εδώ βασίζονται σε ένα δείγμα μηχανικής της
AMD Strix Point APU
, κυρίως του Ryzen AI 9 365, οπότε πάρτε τα με λίγο αλάτι καθώς μπορεί να μην είναι αντιπροσωπευτικά του τελικού προϊόντος. Δηλώνει επίσης ρητά ότι το δοκιμαστικό σύστημα εκτελούσε ανεπίσημο υλικολογισμικό/λογισμικό συστήματος.
Αρχικά, ο David απέκτησε πρόσβαση σε έναν πρώιμο φορητό υπολογιστή AMD Strix Point που φέρεται να διαθέτει το Ryzen AI 9 365 SKU. Η πλατφόρμα δοκιμής έκανε χρήση μνήμης LPDDR5x-7500 σε χωρητικότητα 32 GB. Η κύρια εστίαση της σημερινής δοκιμής είναι το IPC και το Throughput που ξεκινά με το InstructionRate Tool για τη μέτρηση της απόδοσης/λανθάνουσας ισχύος εντολών τριών γενεών Zen CPU, συμπεριλαμβανομένων των αρχιτεκτονικών Zen 3, Zen 4 και Zen 5.
Ο David αναφέρει ότι, ενώ το Zen 5 έχει βελτιώσεις χάρη στον πρωτοποριακό σχεδιασμό του, η αρχιτεκτονική έχει επίσης μερικά μειονεκτήματα τα οποία είναι τα παρακάτω:
- Η απόδοση των διαφόρων βαθμωτών εντολών ALU έχει αυξηθεί σημαντικά, αλλά επειδή ο αριθμός των διανυσματικών μονάδων στο κινητό Zen 5 είναι κατά το ήμισυ σε σύγκριση με τον επιτραπέζιο υπολογιστή και τον διακομιστή, η απόδοση SIMD σε αυτήν τη δοκιμή παραμένει αμετάβλητη σε σύγκριση με το Zen 4. Ακόμη και στο Zen 5 πυρήνα με μισές διανυσματικές μονάδες, οι λειτουργίες αποθήκευσης SIMD όλων των πλατών εξακολουθούν να διπλασιάζονται σε σύγκριση με την προηγούμενη γενιά και η απόδοση αποθήκευσης φορτίου SIMD φτάνει το 1:1.
-
Η ικανότητα επεξεργασίας υποκαταστημάτων έχει βελτιωθεί σημαντικά, με τον αριθμό των μη ληφθέντων υποκαταστημάτων που μπορούν να υποβληθούν σε επεξεργασία ανά κύκλο να αυξηθεί από δύο σε τρία,
και δύο ληφθέντες κλάδοι μπορούν να υποβληθούν σε επεξεργασία ανά κύκλο
. Αυτό θα πρέπει να σχετίζεται με τη νέα σχεδίαση του μπροστινού μέρους. - Η καθυστέρηση των υπολογισμών προσθήκης ακεραίων 128/256/512 bit SSE/AVX/AVX512 SIMD έχει αυξηθεί σε 2 κύκλους. Αυτή η αλλαγή μπορεί να είναι για να διευκολύνει τη διατήρηση υψηλών συχνοτήτων.
- Η απόδοση των πράξεων προσθήκης ακεραίων SIMD 128/256 bit μειώνεται στο μισό σε σύγκριση με το Zen 4, αλλά τα 512 bit παραμένουν αμετάβλητα. Εικάζεται ότι αυτό το πρόβλημα υπάρχει μόνο σε πυρήνες Zen 5 με μειωμένο στο μισό SIMD, το οποίο μπορεί να σχετίζεται με την κατανομή θυρών.
- Καταργήθηκε η λειτουργία nop fusion που εισήχθη στο Zen 4. Δεν είναι πλέον δυνατή η συγχώνευση μιας εντολής nop με μια άλλη εντολή στο ίδιο macro-op.
- Προσάρμοσε τη διεκπεραίωση ορισμένων λειτουργιών λογικού καταχωρητή, ενοποιώντας τη διεκπεραίωση ορισμένων λειτουργιών mov και ορισμένων λειτουργιών μηδενισμού καταχωρητή στο 5, κάτι που είναι μια μικτή βελτίωση σε σύγκριση με το Zen 4.
Οι δοκιμές επικεντρώνονται επίσης στο μπροστινό μέρος του παράλληλου διπλού σωλήνα, το οποίο θα πρέπει να επηρεάσει την ανάκτηση εντολών, την αποκωδικοποίηση και την κρυφή μνήμη macro-op. Αναφέρεται ότι εκτελώντας εντολές NOP διαφορετικών μηκών & αριθμών, μπορούν να παρατηρηθούν οι διαφορές μεταξύ Zen 4 και Zen 5. Οι παρατηρήσεις καταλήγουν ως εξής:
- Το Zen 5 χρησιμοποιεί σχεδιασμό πολλαπλών μπροστινών παρόμοιων με το Tremont αλλά ευρύτερο, χρησιμοποιώντας δύο αποκωδικοποιητές x86 4 πλάτους και κρυφές μνήμες macro-op τουλάχιστον 8 πλάτους για την υλοποίηση μετονομασιών 8 πλάτους.
-
Σκεφτείτε το ακόλουθο φαινόμενο
- Το Zen 5 δεν μπορεί να κάνει το εύρος ζώνης αποκωδικοποίησης x86 να υπερβαίνει το 4 όταν εκτελούνται διαδοχικές εντολές NOP σε ένα μόνο νήμα.
- Στην ενότητα εντολών απόδοσης, δοκιμάστηκε ότι δύο ληφθέντες κλάδοι μπορούν να υποβληθούν σε επεξεργασία σε έναν μόνο κύκλο.
- Είναι εύλογο να υποθέσουμε ότι το Zen 5 δεν χρησιμοποιεί μια λύση προσωρινής μνήμης ILD προ-αποκωδικοποίησης παρόμοια με το Gracemont, αλλά πρέπει να επιτρέπει σε δύο αποκωδικοποιητές να λειτουργούν ταυτόχρονα όταν ο προγνωστικός κλάδος προβλέπει μια ληφθείσα διακλάδωση, δηλαδή αφήνει απευθείας έναν από τους αποκωδικοποιητές να ξεκινήσει την αποκωδικοποίηση από την επόμενη διεύθυνση στόχου υποκαταστήματος. Από αυτή την άποψη, η AMD πρέπει ακόμα να βασίζεται στην κρυφή μνήμη macro-op για να επιτύχει υψηλή απόδοση σε σενάρια με αραιούς κλάδους.
- Το Zen 5 όχι μόνο υποστηρίζει την αποκωδικοποίηση εντολών x86 από δύο τοποθεσίες στον ίδιο κύκλο, αλλά υποστηρίζει επίσης τη λήψη εντολών από δύο θέσεις στην κρυφή μνήμη macro-op στον ίδιο κύκλο, για την επίτευξη δύο ληφθέντων διακλαδώσεων ανά κύκλο εντός της κάλυψης του macro-op κρύπτη;
- Όταν ο πυρήνας εκτελεί δύο νήματα SMT, το καθένα μπορεί να μονοπωλήσει έναν αποκωδικοποιητή, έτσι ώστε το όριο απόδοσης αποκωδικοποίησης x86 ολόκληρου του πυρήνα να φτάσει το 8 στις περισσότερες περιπτώσεις.
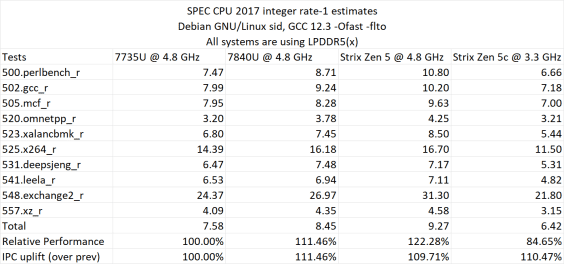
Στη συνέχεια, οι δοκιμές προχωρούν στις περισσότερες πτυχές απόδοσης των APU της AMD Strix Point. Για άλλη μια φορά, χρησιμοποιείται το τσιπ Ryzen AI 9 365, αλλά αυτή τη φορά, έρχεται σε αντίθεση με το Ryzen 7 7735U (Zen 3), το Ryzen 7 7840U (Zen 4) και το προαναφερθέν Ryzen AI 9 365 (Zen 5), αλλά αυτή τη φορά και οι δύο πυρήνες Zen 5 και Zen 5C που είναι διαθέσιμοι στο τσιπ που δοκιμάζεται. Οι πυρήνες Zen 5C λειτουργούν σε πολύ χαμηλότερο ρολόι μόλις 3,30 GHz ενώ οι πυρήνες Zen 5 και τα άλλα δύο τσιπ ρυθμίζονται σε σταθερό ρυθμό ρολογιού 4,8 GHz.
Η απόδοση αξιολογήθηκε στο πλαίσιο του SPEC CPU 2017 και του Geekbench 6 (μονού πυρήνα και πολλαπλών πυρήνων). Στην SPEC CPU 2017, το τσιπ AMD Zen 5 παρουσιάζει αύξηση +9,71% σε σχέση με την προσφορά Zen 4 και αύξηση 22,28% σε σχέση με την προσφορά Zen 3. Οι πυρήνες Zen 5C σχεδόν ταιριάζουν με το Zen 4 IPC σε χαμηλότερο ρολόι.
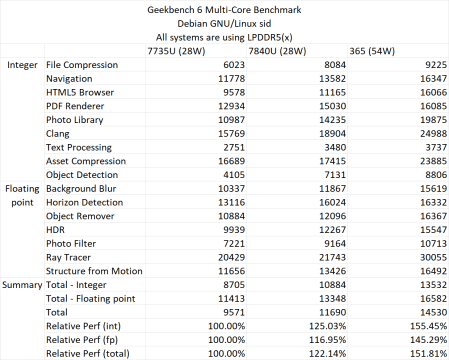
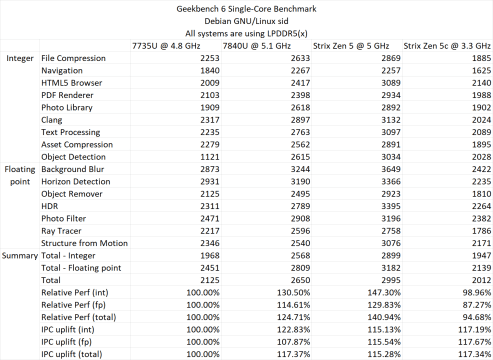
Στο Geekbench 6, η σχετική βελτίωση της απόδοσης σε σχέση με το Zen 3 είναι έως και 40,94% έναντι του Zen 3 και του Zen 4, είναι περίπου 13,1%. Αυτοί οι αριθμοί είναι μόνο σε έναν πυρήνα. Με δοκιμές πολλαπλών πυρήνων, οι APU “Strix Point” Zen 5 έχουν αύξηση 55,45% σε σχέση με το Zen 3 και 24,3% βελτίωση σε σχέση με το Zen 4, αλλά πρέπει να σημειωθεί ότι τα τσιπ Zen 3 και Zen 4 εκτελούσαν TDP 28 W έναντι 54 W. της Ryzen AI 9 365 APU.
SPEC CPU 2017 IPC (Gen-To-Gen)
- Ζεν 3 – 100,00%
- Ζεν 4 – 111,46%
- Ζεν 5 – 109,71%
SPEC CPU 2017 Perf (Σχετικό)
- Ζεν 3 – 100,00%
- Ζεν 4 – 111,46%
- Ζεν 5 – 122,28%
Geekbench 6 ST IPC (Gen-To-Gen)
- Ζεν 3 – 100,00%
- Ζεν 4 – 117,37%
- Ζεν 5 – 115,28%
Geekbench 6 ST Perf (Σχετικός)
- Ζεν 3 – 100,00%
- Ζεν 4 – 124,71%
- Ζεν 5 – 140,94%
Η ανάρτηση του ιστολογίου του David αναφέρεται εκτενώς στις διάφορες αρχιτεκτονικές πτυχές της αρχιτεκτονικής Zen 5
που δεν θα τροφοδοτεί μόνο τις APU Ryzen AI
300
“Strix Point” αλλά και πολλές διαφορετικές CPU, όπως η οικογένεια επιτραπέζιων υπολογιστών Ryzen 9000 “Granite Ridge”, η οικογένεια διακομιστών 5ης γενιάς EPYC “Turin” και διάφορες άλλες APU για επιτραπέζιους και φορητούς υπολογιστές .
Αυτό που γνωρίζουμε επίσημα είναι ότι οι πυρήνες Zen 5 έρχονται με μέση αύξηση IPC
16
% και κυμαίνεται για διαφορετικούς φόρτους εργασίας, επομένως για άλλη μια φορά, θα συμβουλεύσουμε τους αναγνώστες μας να λάβουν αυτά τα αποτελέσματα με λίγο αλάτι. Η πρώτη κυκλοφορία του Zen 5 αναμένεται με τις Strix APU στα μέσα Ιουλίου, ακολουθούμενη από τσιπ επιτραπέζιου υπολογιστή υψηλής απόδοσης Ryzen 9000 στα τέλη Ιουλίου, οπότε μείνετε συντονισμένοι για περισσότερες πληροφορίες.
Πηγή ειδήσεων:
Ντέιβιντ Χουάνγκ
VIA:
wccftech.com
0